Centering / Footing
RAPALA design blog 001
About RAPALA
I ran into an interesting design design problem and after realizing how interesting it was I wanted to write on it.
But let me circle for a bit. The trouble with roguelikes is they are a slipperly slope. No matter which one you start playing, you end up playing (ok, trying) Dwarf Fortress, and after that, you end up making your own.
(Here I mean Roguelike to mean, a game with blocks of characters, where you move one tile at a time, maybe or not with permadeath, maybe or not auto generated. So ZZT or Megazeux would be a roguelike by my terrible definition, but please don't call the game police on me...)
So after trying my hand at Dwarf Fortress a few months back, I'm vaguely making (ok, starting) one.
RAPALA has a few goals:
- Hand crafted spaces
- Easy to work on
- Creativity oriented sandboxy
- User made areas and things
- Laid back and evocative
Right now it looks like this:

Clever Isometry
Something immediately useful to do with 2D games is to set the basis for your sprites to be their feet.
Consider a statue, and grass, both distinct sprites:
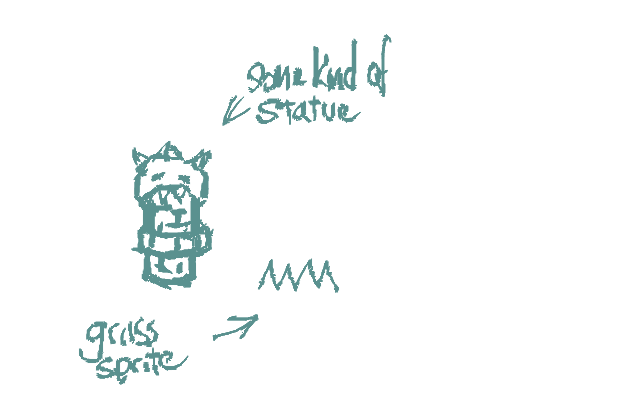
First off, they are different sizes and have different (visual, if not physical) bounding boxes:
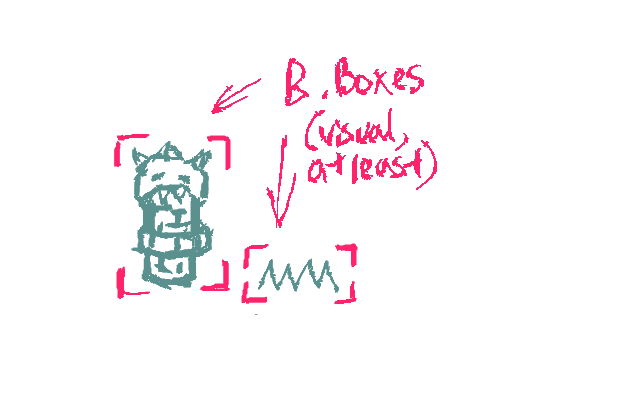
Those bounding boxes have center points, of course:

So let's imagine they are at the same spot, grass on top. What we're going for: the grass is covering the statue, partially...

Hmn. That didn't work out. We can fix this by defining an anchor point at the "foot" of each sprite:

Now when they're at the same spot, if we put the grass on top, it looks like what we were going for:

Or, does it? I mean, does it have to be this way? And if it is this way, could it be even more so? Does this system give us the flexibility for some of the blades of grass to be behind the statue, some in front? Does it let the statue cast a shadow on the individual blades of grass? What about animation?
The whole purpose of anchor points is to create a kind of "fake" 3D, or isometry, which is just 3D with the camera pulled infinitely back:

A line stretching infinitely into the known and into the unknown infinitelyer yet...
Really this system that seemed perfect has a lot of shortcomings. We can solve them with better technology.
Or with this:
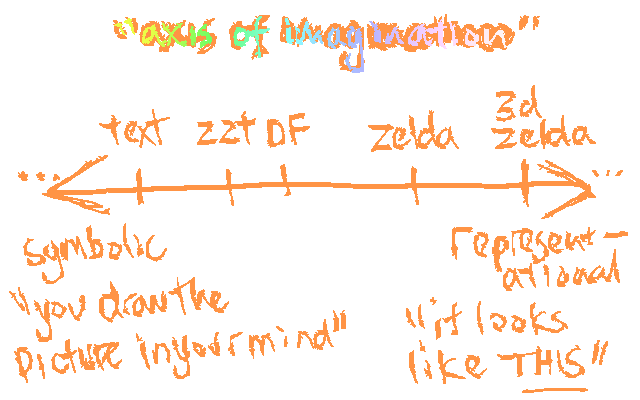
(Fig. 1: The Axis of Imagination, plotted here with every known genre of videogame.)
Anchor points are not objectively better just because they "fix" the grass-covering-statue problem. A step towards "fixing" a broken visual element could also be seen as a step toward making it more representational. Which may or may not be what we really want.
On the left side of this axis you have pure text. "The statue is covered by the grass, partially." What is to the left of it? Shorter words? Nonsense words? Pure symbol-writing? Shapes? A gamecube, dragged behind a pickup truck?
On the right we have, of couse, fancy 3D games.
I think it bears remembering that even the fanciest technology we have is still just somewhere on this axis, and maybe not where we think it is. It's easy to look at a screenshot of (say) Assasin's Creed: Odyssey and think, "this is so close to life!" but actually, the way the visual (and other) elements are idealized is still abstract in many ways. Is the athleticism of the Assassin something that punches it left, here? What about her ability to kill in cold blood?
But actually it's a stranger fact still that the (very) beautiful 3D representations in modern videogames are idealized in a way that makes it obvious they aren't really real. The water is a symbol for how water looks, but in a certain mathematical model. This makes it convincing in that we say, "wow, that is water" but actually don't we mean, "wow, that really captures the essence of water" which is to say, "wow, I've seen water— but this makes me appreciate it more, somehow, because the aspects of it that are beautiful have been brought out so sublimely!"
This is a pretty long tangent but below is a really interesting video comparing real-life (well, someone's real life, not mine) to Project CARS, a game that I think explicitly aims for realism. It's interesting because I think it's more convincing, but with less apparent detail:
Less is less, but like, that's just the definition of less: it's less.
If it's an axis, then we can also move in the other direction, if we choose. One way to model the "representational-ness" of something is to think about how many creative decisions are part of the thing itself. This could be, "how many polygons does it have" but also "can it be a different size from other things?" or "can it have a different center from other things?"
Each question that the thing answers in and of itself we could call a dimension of choice.
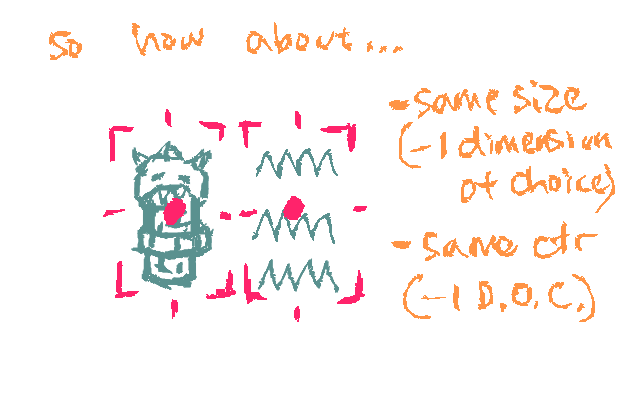
If we start to think in these terms, we realize that e.g., making something black and white does, in a sense, make it less representational and more abstract, since it's up to the viewer to decide what color things are (in their own experience of color.) But let's stop here-- I'm not trying to reduce this to a formula, just give a tool for reasoning about it.
In the end, when we place these "things" (sprites in this case, but could also be words) in front of the viewer they are going to decode them using the context of things they have already experienced. I think the argument can be made that they are using their imagination more, than if more detail were presented in the thing itself.
So:

With this, the viewer will be the one to decide how, exactly, the grass might be covering the statue. Only the bottom of it? Or is it tall grass, covering most of it? Or do they even process it in that much detail, but instead create their own internal symbol-logic or it, one that it is itself, abstract?
(Another tangent: does realism or representationalism have a calming, less engaging but more reflecting effect in and of itself? What I mean is, is it like riding a bus, where images passively pass you by, and your thoughts drift, versus riding a bike, where you have to interpret everything you see concretely and are more "in the moment"? I think both are good.)
In conclusion, I am lazy
A notable and very important aspect of this "fewer dimensions of choice" is, it's less work (overall.) Describing a mountain is, probably, a faster process than painting it, which is probably a faster process than modeling it in 3D.
So, surprisingly, not using anchor points fits the goals of RAPALA better:
- Easier to add art, because we don't have to think about size or anchor points
- Easier to place it, because we aren't trying to create believable isometric 3D
- Easier to program it, because fewer dimensions of choice probably means fewer variables or conditions
- Importantly, "we" here means both me and players, since it's a creatively-oriented game
That's all I wanted to write on this.
◀ Back